
命名实体识别(Named Entity Recognition,NER)是NLP一项基础任务。是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。NER是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具。命名实体识别的准确度,决定了下游任务的效果。
1 命名实体识别的概念
要解释NER,首先要理解什么算是实体,实体就是具有特定意义的实例。
在学术上NER所涉及的命名实体一般包括3大类(实体类,时间类,数字类)和7小类(人名、地名、组织机构名、时间、日期、货币、百分比)。
实际应用中,NER模型通常只要识别出人名、地名、组织机构名、日期时间即可,一些系统还会给出专有名词结果(比如缩写、会议名、产品名等)。货币、百分比等数字类实体可通过正则搞定。另外,在一些应用场景下会给出特定领域内的实体,如书名、歌曲名、期刊名等。
所谓实体识别,就是一个从语料中提取出想要获取到的实体类型的过程。
2.研究现状:
命名实体识别只是在有限的文本类型(主要是新闻语料中)和实体类别(主要是人名、地名、组织机构名)中取得了不错的效果;与其他信息检索领域相比,实体命名评测预料较小,容易产生过拟合;命名实体识别更侧重高召回率,但在信息检索领域,高准确率更重要;通用的识别多种类型的命名实体的系统性能很差。
3.命名实体识别的数据标注方式
NER是一种序列标注问题,因此他们的数据标注方式也遵照序列标注问题的方式,主要是BIO和BIOES两种。这里直接介绍BIOES,明白了BIOES,BIO也就掌握了。
先列出来BIOES分别代表的含义:
- B,即Begin,表示开始
- I,即Intermediate,表示中间
- E,即End,表示结尾
- S,即Single,表示单个字符
- O,即Other,表示其他,用于标记无关字符
例:使用BIOES对“我在人民广场吃着炸鸡”这句话,进行标注,每个字对应的结果就是:
[B-PER,E-PER,O, B-LOC,I-LOC,I-LOC,E-LOC,O,O,O,O]
4.命名实体识别的方法介绍
1)HMM,MEMM和CRF等机器学习算法
HMM和CRF很适合用来做序列标注问题,早期很多的效果较好的成果,都是出自这两个模型。两种模型在序列标注问题中应用:
【NLP】用于语音识别、分词的隐马尔科夫模型HMM
【NLP】用于序列标注问题的条件随机场(Conditional Random Field, CRF)
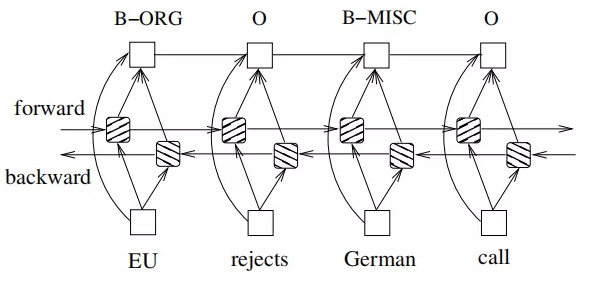
2)LSTM+CRF
目前做NER比较主流的方法就是采用LSTM作为特征抽取器,再接一个CRF层来作为输出层,如下图所示:
3)CNN+CRF
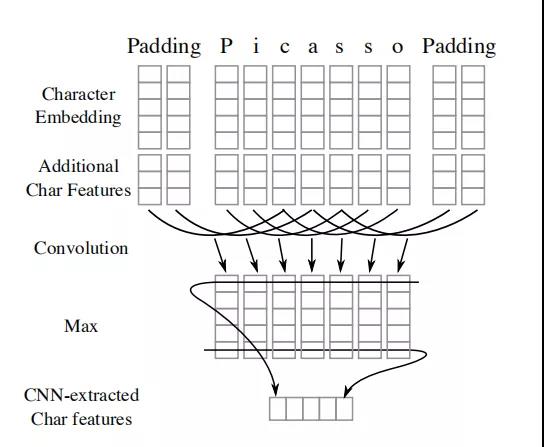
CNN虽然在长序列的特征提取上有弱势,但是CNN模型可有并行能力,有运算速度快的优势。膨胀卷积的引入,使得CNN在NER任务中,能够兼顾运算速度和长序列的特征提取。
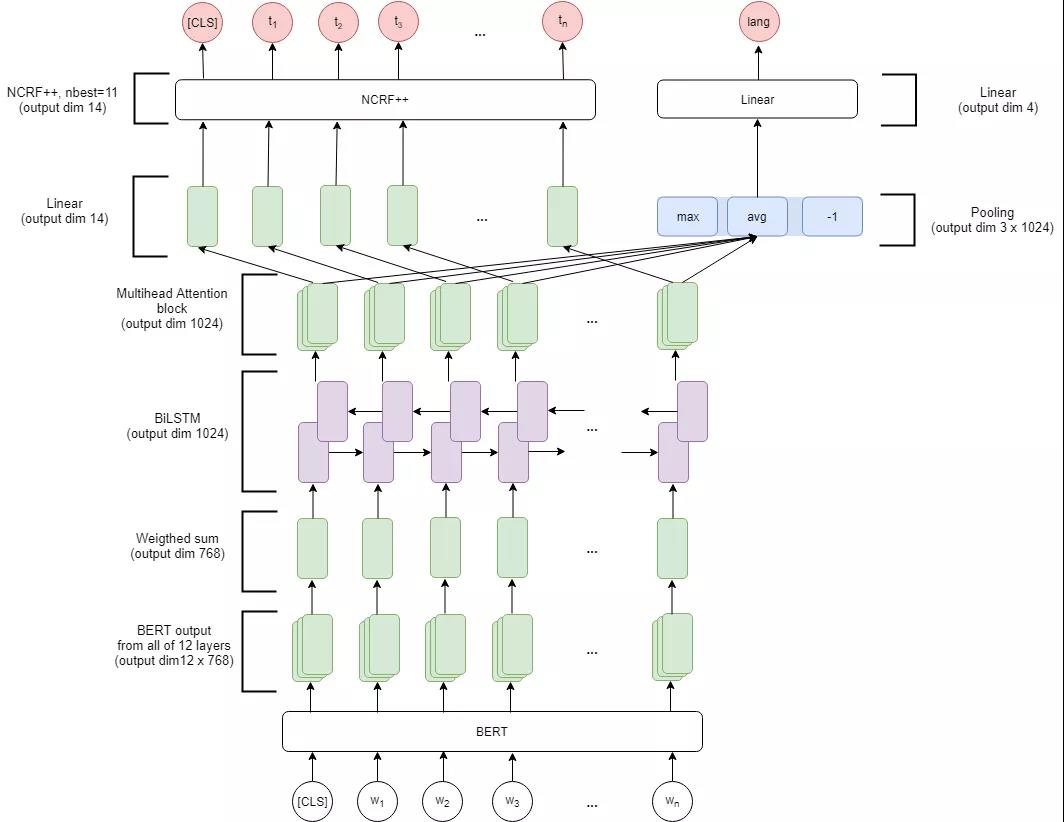
4)BERT+(LSTM)+CRF
BERT中蕴含了大量的通用知识,利用预训练好的BERT模型,再用少量的标注数据进行FINETUNE是一种快速的获得效果不错的NER的方法。
- 作者: Chris Yan
- 链接: https:/Yansz.github.io/2019/01/10/NER的概念/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!