
命名实体识别(Named Entity Recognition,NER)是NLP中一项非常基础的任务。NER是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具。
1 LSTM+CRF
在NLP领域,有那么一段时间,LSTM是“最红”的特征抽取器,NER中也使用LSTM来进行特征抽取。
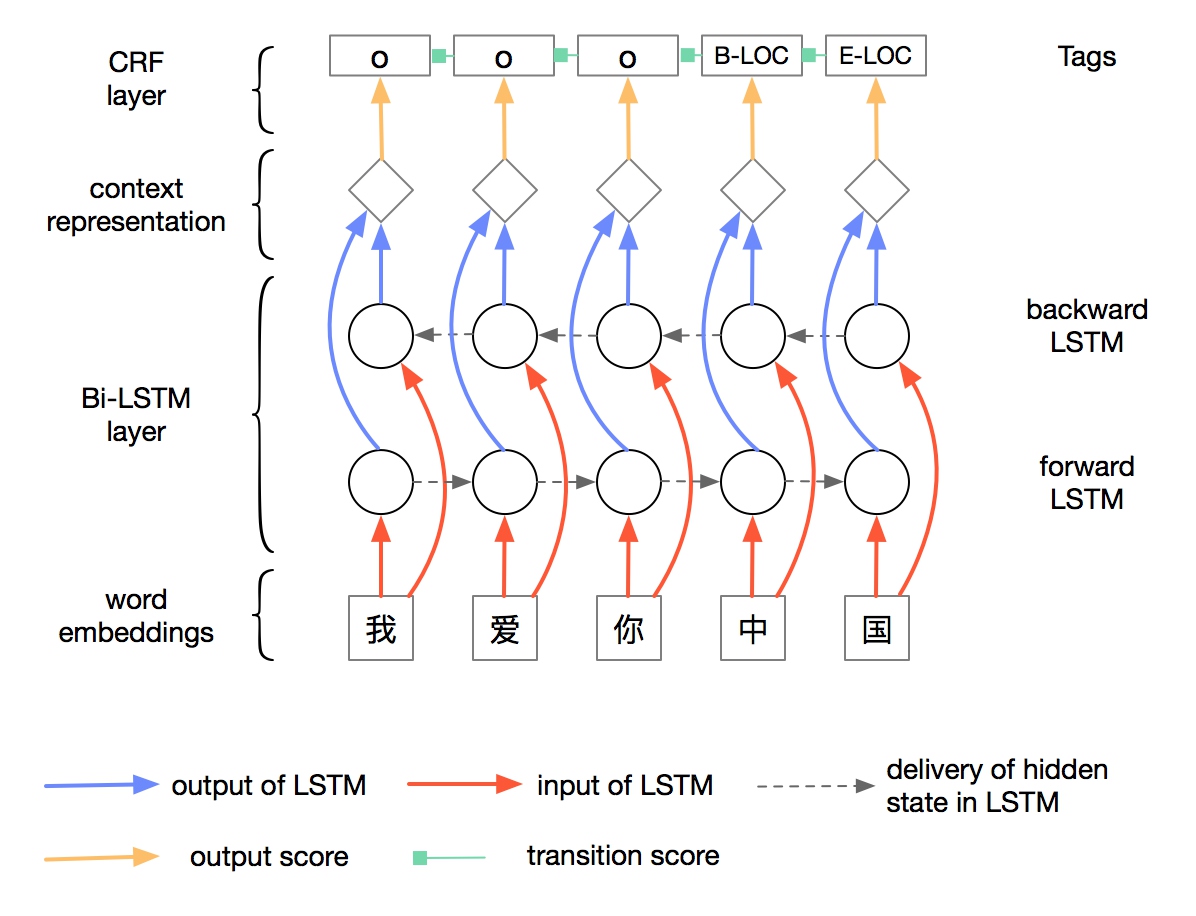
上述架构图中采用的双向 LSTM 架构和之前的 LSTM 架构略有不同,具体公式如下:
$${\boldsymbol{i}{t}=\sigma\left(\boldsymbol{W}{x i} \boldsymbol{x}{t}+\boldsymbol{W}{h i} \boldsymbol{h}{t-1}+\boldsymbol{W}{c i} \boldsymbol{c}{t-1}+\boldsymbol{b}{i}\right)} \
{\boldsymbol{c}{t}=\left(1-\boldsymbol{i}{t}\right) \odot \boldsymbol{c}{t-1}+\boldsymbol{i}{t} \odot \tanh \left(\boldsymbol{W}{x c} \boldsymbol{x}{t}+\boldsymbol{W}{h c} \boldsymbol{h}{t-1}+\boldsymbol{b}{c}\right)} \
{\boldsymbol{o}{t}=\sigma\left(\boldsymbol{W}{x o} \boldsymbol{x}{t}+\boldsymbol{W}{h o} \boldsymbol{h}{t-1}+\boldsymbol{W}{c o} \boldsymbol{c}{t}+\boldsymbol{b}{o}\right)} \
{\boldsymbol{h}{t}=\boldsymbol{o}{t} \odot \tanh \left(\boldsymbol{c}{t}\right)}
\end{array}$$
对比前述 LSTM 表示方式可见,这里采用了 ($1− i_t$) 替换遗忘门,同时输入门依赖 LSTM
记忆单元历史信息 $c_{t−1}$,输出门依赖于更新后的当前 LSTM 记忆单元信息 $c_t$。给定上下
文下,每个词的特征表示由双向 LSTM 各自输出的 $h_t$ 拼接而成$\boldsymbol{h}{t}=\left[\overrightarrow{\boldsymbol{h}}{t} ; \overleftarrow{\boldsymbol{h}_{t}}\right]$ 。给定每个
词当前上下文下的向量表示后,即可以用于进行命名实体识别。
假设命名实体中有两类实体:人名 (PER),地名 (LOC),分别采用 B 和 I 两类标签表示词在命名实体中处于开始和中间位置,用 O 表示其他非命名实体词,则命名实体识别问题转化为序列标注问题,该问题可以采用 CRF 模型进行解决。给定序列
$$\boldsymbol{H}=\left(\boldsymbol{h}{1}, \boldsymbol{h}{2}, \ldots, \boldsymbol{h}_{n}\right)$$
期望生成上述序列对应的标注序列:
$$y=\left(y_{1}, y_{2}, \ldots, y_{n}\right)$$
采用 CRF 表示方式,序列对应的矩阵$H$和标注对应的向量 $y$联合权重表示形式如下:
$$
s(\boldsymbol{H}, \boldsymbol{y})=\sum_{i=0}^{n} A_{y_{i}, y_{i+1}}+\sum_{i=1}^{n} P_{i, y_{i}}
$$
分析一下这个模型,看数据的流转和各层的作用。
1.embedding layer 将中文转化为字向量,获得输入embedding
2.将embedding输入到BiLSTM层,进行特征提取(编码),得到序列的特征表征,logits。
3.logits需要解码,得到标注序列。将其输入到解码CRF层,获得每个字的序列。
该模型的重点有两个:
1. 引入双向LSTM层作为特征提取工具,LSTM拥有较强的长序列特征提取能力,是个不错的选择。双向LSTM,在提取某个时刻特征时,能够利用该时刻之后的序列的信息,无疑能够提高模型的特征提取能力。
2. 引入CRF作为解码工具。中文输入经过双向LSTM层的编码之后,需要能够利用编码到的丰富的信息,将其转化成NER标注序列。通过观察序列,预测隐藏状态序列,CRF无疑是首选。
2 ID-CNN+CRF
对于膨胀卷积先做一个简单的介绍。
Dilated/Atrous Convolution(中文叫做空洞卷积或者膨胀卷积))或者是Convolution with holes。从字面上就很好理解,就是在标准的卷积里注入空洞,以此来增加感受野。
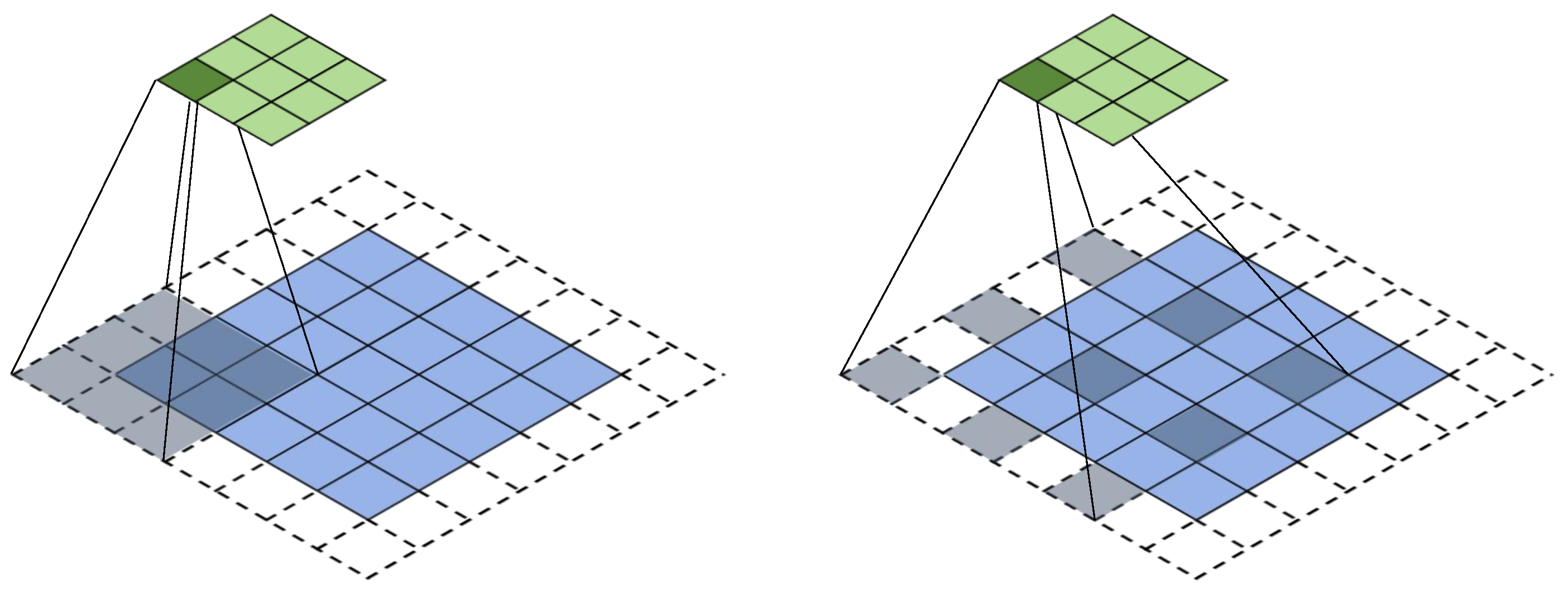
如上图所示,相比原来的正常卷积,膨胀卷积多了一个超参数,称之为膨胀率(dilation rate),指的是kernel的间隔数量(例如,正常的卷积是膨胀率是1)。
“膨胀”的好处是,不做池化,不损失信息的情况下,增大了感受野,让每个卷积输出都包含较大范围的信息。
《Fast and Accurate Entity Recognition with Iterated Dilated Convolutions》一文中提出在NER任务中,引入膨胀卷积,一方面可以引入CNN并行计算的优势,提高训练和预测时的速度;另一方面,可以减轻CNN在长序列输入上特征提取能力弱的劣势。
具体使用时,dilated width会随着层数的增加而指数增加。这样随着层数的增加,参数数量是线性增加的,而感受野却是指数增加的,这样就可以很快覆盖到全部的输入数据。
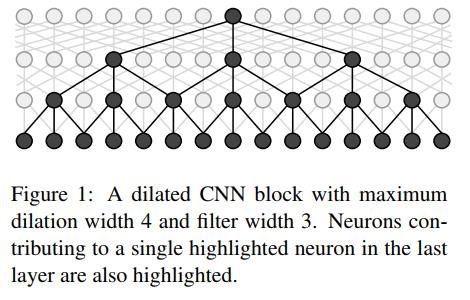
LSTM+CRF和ID-CNN+CRF两种模型其实都是同一个架构:深度学习特征提取+CRF解码。现在绝大部分的NER任务都是采用这样的一套框架。
- 作者: Chris Yan
- 链接: https:/Yansz.github.io/2019/01/11/NER中的两种DL模型/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!