
本篇整理 Transformer 架构,及在 Transformer 基础上衍生出来的 BERT 模型,最后给出
相应的应用案例。
1.Transformer的架构
Transformer 网络架构架构由 Ashish Vaswani 等人在 [Attention Is All You Need]一文中提出,并用于机器翻译任务,和以往网络架构有所区别的是,该网络架构中,编码器和解码器没有采用 RNN 或 CNN 等网络架构,而是采用完全依赖于注意力机制的架构。网络架构如下所示:
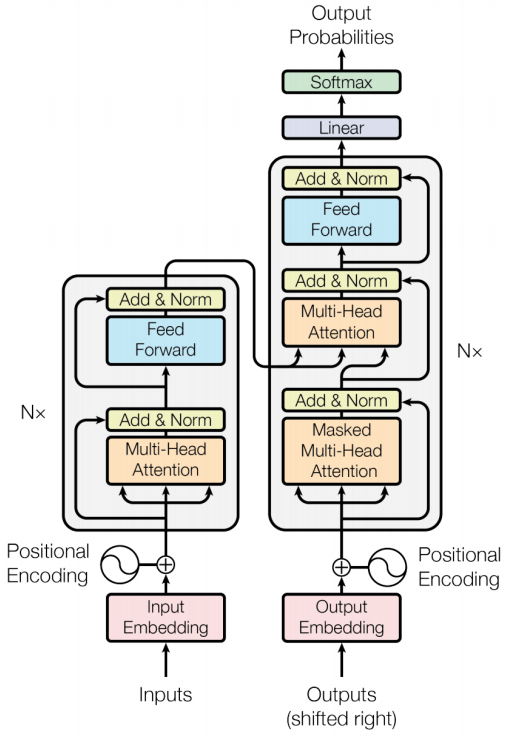
该网络架构中引入了多头注意力机制,该机制的网络架构如下所示:
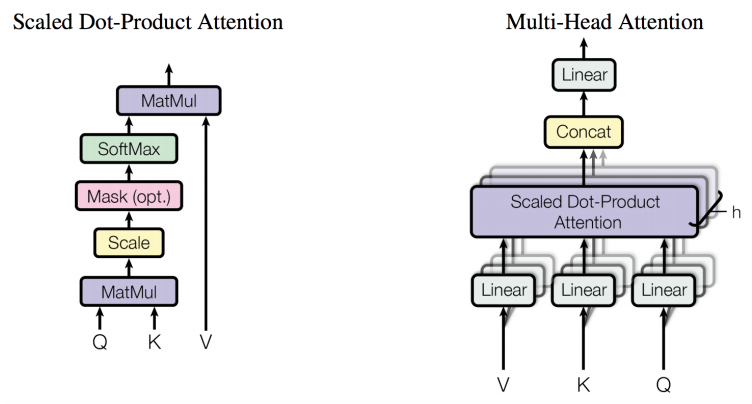
这里有必要对多头注意力机制进行一定的解释。假设输入数据的 batch size 为$B$,输入数据的最大长度为$F$,输出数据的最大长度为$T$,共有$N$个注意力头,每个注意力头的输出维度为$H$,则输入/输出数据中每个词的 Embedding 的维度为 $E=N×H$,且注意力头中每个头对应的$\boldsymbol{W}^{Q}, \boldsymbol{W}^{K} ,\boldsymbol{W}^{V}
$矩阵均属于$\mathbb{R}^{E \times H}$。考虑到编码器和解码器涉及三个注意过程,且输入有所不同,这里分别来看。
2.编码器自注意力
考虑输入数据为$\mathbf{X} \in \mathbb{R}^{B \times F \times E}$,对输入数据应用如下线性变换:
$$
\begin{aligned}
&\mathbf{Q}=\mathbf{X} \mathbf{W}^{Q}, \quad\left(\mathbf{W}^{Q} \in \mathbb{R}^{E \times H} \Rightarrow \mathbf{Q} \in \mathbb{R}^{B \times F \times H}\right)\
&\mathbf{K}=\mathbf{X} \mathbf{W}^{K}, \quad\left(\mathbf{W}^{K} \in \mathbb{R}^{E \times H} \Rightarrow \mathbf{K} \in \mathbb{R}^{B \times F \times H}\right)\
&\mathbf{V}=\mathbf{X} \boldsymbol{W}^{V}, \quad\left(\boldsymbol{W}^{V} \in \mathbb{R}^{E \times H} \Rightarrow \mathbf{V} \in \mathbb{R}^{B \times F \times H}\right)
\end{aligned}
$$
在上述变换基础上进行如下计算,得到输入中每个词和自身及其他词之间的关系权重
$$
\mathbf{S}=\operatorname{softmax}\left(\frac{\mathbf{Q K}^{\top}}{\sqrt{H}}\right)
$$
上述变换 $K^T$ 表示对张量的最内部矩阵进行转置,因此$\mathbf{K}^{\top} \in \mathbb{R}^{B \times H \times F}$,$\mathrm{QK}^{\top}$表示相同维度下张量 Q 和张量 $K^T$ 最内部矩阵执行矩阵乘法运算 (即 numpy.matmul 运算),因此有$\mathbf{S} \in \mathbb{R}^{B \times F \times F}$,该张量表示输入数据中每个词和自身及其他词的关系权重,每一行的得分之和为 1,即
$$
\forall i, j \quad \operatorname{np.sum}(\mathbf{S}[i, j,:])=1
$$
基于该得分即可得到,每个词在当前上下文下的新的向量表示,公式如下:
$$
\mathbf{x}^{h}=\mathbf{S V} \quad \Rightarrow \mathbf{X}^{h} \in \mathbb{R}^{B \times F \times H}
$$
考虑到 Transformer 采用了 N 个注意力头,因此最终产生了集合大小为 N 的注意力集合$\left{\mathbf{X}^{h_{1}}, \ldots, \mathbf{X}^{h_{N}}\right}$,将该集合中中的所有张量按照最后一个维度进行拼接,并采用矩阵$\boldsymbol{W}^{O} \in \mathbb{R}^{E \times E}$进行变换,得到最终生成的自注意力输入数据,公式如下:
$$
\mathbf{X}^{a}=\text { numpy.concatenate }\left(\left(\mathbf{X}^{\mathrm{h}{1}}, \ldots, \mathbf{X}^{\mathrm{h}{\mathrm{N}}}\right), \text { axis }=-1\right) \boldsymbol{W}^{O}
$$
因此有$\mathbf{X}^{a} \in \mathbb{R}^{B \times F \times E}$。
考虑到多头注意力可以并行运算,为了充分发挥向量化计算并行效率,实际实现中往往采用如下表示方案:
$$
\begin{aligned}
&\mathbf{X}^{\text {par }}=\text { reshape }(\mathbf{X}, \text { to shape }=[B \times F, N \times H])\
&\begin{array}{ll}
{\mathbf{Q}^{p a r}=\mathbf{X}^{p a r} \boldsymbol{W}^{Q^{p a r}}} & {\left(\boldsymbol{W}^{Q^{p a r}} \in \mathbb{R}^{(N \times H) \times(N \times H)} \Rightarrow \mathbf{Q}^{p a r} \in \mathbb{R}^{(B \times F) \times(N \times H)}\right)} \
{\mathbf{K}^{p a r}=\mathbf{X}^{p a r} \boldsymbol{W}^{K^{p a r}}} & {\left(\boldsymbol{W}^{K^{p a r}} \in \mathbb{R}^{(N \times H) \times(N \times H)} \Rightarrow \mathbf{K}^{p a r} \in \mathbb{R}^{(B \times F) \times(N \times H)}\right)} \
{\text { V }^{p a r}=\mathbf{X}^{p a r} \boldsymbol{W}^{V^{p a r}}} & {\left(\boldsymbol{W}^{V^{p a r}} \in \mathbb{R}^{(N \times H) \times(N \times H)} \Rightarrow \mathbf{V}^{p a r} \in \mathbb{R}^{(B \times F) \times(N \times H)}\right)}
\end{array}
\end{aligned}
$$
在上述并行计算基础上通过如下计算得到词和自身及其他词的关系权值:
$$
\begin{array}{l}
{\left.\mathbf{v}^{p a r}=\text { numpy.reshape (Vpar, }(B, F, N, H)\right)} \
{ \text { v’art }\left.=\text { numpy. transpose (V }^{p a r}, \text { axes }=[0,2,1,3]\right) \Rightarrow \mathbf{V}^{p a r^{t}} \in \mathbb{R}^{B \times N \times F \times H}} \
{\mathbf{X}^{h}=\mathbf{S}^{p a r} \mathbf{v}^{p a r^{t}} \Rightarrow \mathbf{X}^{h} \in \mathbb{R}^{B \times N \times F \times H}} \
{\mathbf{X}^{h}=\text { numpy. transpose }\left(\mathbf{X}^{h}, \text { axes }=[0,2,1,3]\right) \Rightarrow \mathbf{X}^{h} \in \mathbb{R}^{B \times F \times N \times H}} \
{\left.\mathbf{X}^{h}=\text { numpy.reshape }\left(\mathbf{X}^{h}, F, N \times H\right)\right) \Rightarrow \mathbf{X}^{h} \in \mathbb{R}^{B \times F \times E}}
\end{array}
$$
3.解码器自注意力
解码器的自注意力和编码器的自注意力基本完全一致,需要注意的是解码过程是one by one的生成过程,因此输出数据中的每个词在进行自注意力的过程时,仅可以看到当前输出位置的所有前驱词的信息,因此需要对输出数据中的词进行掩码操作,该操作即对应上面的左图上的掩码操作。该掩码操作相当于执行如下操作:
$$
\begin{aligned}
\mathbf{A} &=\mathbf{Q K}^{\top}+\mathbf{M} \
\mathbf{S}^{p a r} &=\operatorname{softmax}\left(\frac{\mathbf{A}}{\sqrt{H}}\right) \Rightarrow \mathbf{S}^{p a r} \in \mathbb{R}^{B \times N \times T \times T}
\end{aligned}
$$
其中$\mathbf{M} \in \mathbb{R}^{1 \times 1 \times T \times T}$ 为掩码,其最内部矩阵为方阵,该方阵主对角线及以下元素均为 0,主对角线以上元素为$-\infty$。譬如 T = 5 时,最内部方阵内容如下:
$$
\boldsymbol{M}=\left[\begin{array}{ccccc}
{0} & {-\infty} & {-\infty} & {-\infty} & {-\infty} \
{0} & {0} & {-\infty} & {-\infty} & {-\infty} \
{0} & {0} & {0} & {-\infty} & {-\infty} \
{0} & {0} & {0} & {0} & {-\infty} \
{0} & {0} & {0} & {0} & {0}
\end{array}\right]
$$
其余操作和编码器自注意力机制一致,唯一不同的是此时需要向上面那样将输入数据换成 $\mathbf{Y} \in \mathbb{R}^{N \times T \times E}$,因此所有的 $F$ 均需换成 $T$。
4.编码解码注意力
编码解码注意力和自注意力类似,唯一不同的是计算 Q, K, V 使用的数据有所区别,计算
Q 时采用 Y,计算 K 和 V 时采用 X,因此有:
$$
\begin{aligned}
\mathbf{X}^{\text {par }} &=\text {reshape}(\mathbf{X}, \text { to_shape }=[B \times F, N \times H]) \
\mathbf{Y}^{\text {par }} &=\text {reshape}(\mathbf{Y}, \text { to shape }=[B \times T, N \times H]) \
\mathbf{Q}^{\text {ende-par}} &=\mathbf{Y}^{\text {par}} \boldsymbol{W}^{Q \text {ende-par}} \quad\left(\boldsymbol{W}^{Q \text { ende-par }} \in \mathbb{R}^{(N \times H) \times(N \times H)}\right) \
\mathbf{K}^{\text {ende-par}} &=\mathbf{X}^{\text {par}} \boldsymbol{W}^{K^{\text {ende-par}}} \quad\left(\boldsymbol{W}^{K \text {ende-par}} \in \mathbb{R}^{(N \times H) \times(N \times H)}\right) \
\mathbf{V}^{\text {ende-par}} &\mathbf{X}^{\text {par }} \boldsymbol{W}^{\text {Vpar}} \quad\left(\boldsymbol{W}^{\text {Vende-par}} \in \mathbb{R}^{(N \times H) \times(N \times H)}\right)
\end{aligned}
$$
因此有:
$$
\mathbf{S}^{\text {ende-par}}=\operatorname{softmax}\left(\frac{\mathbf{Q}^{\text {ende-par}^{t}} \mathbf{K}^{\text {ende-par}^{t \top}}}{\sqrt{H}}\right) \Rightarrow \mathbf{S}^{\text {ende-par}} \in \mathbb{R}^{B \times N \times T \times F}
$$
$$
\mathbf{y}^{\text {ende-h}}=\mathbf{S}^{\text {ende-par}} \mathbf{V}^{\text {ende-par}} \Rightarrow \mathbf{Y}^{\text {ende-h}} \in \mathbb{R}^{B \times N \times T \times H}
$$
其余计算过程和编码器自注意力机制类似。
- 作者: Chris Yan
- 链接: https:/Yansz.github.io/2019/02/10/Transformer详细讲解/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!