
BERT(Bidirectional Encoder Representation from Transformers) 网络架构由 Jacob Devlin 等人提出用于预训练,学习在给定上下文下给出词的 Embedding 表示。BERT 采用了 Transformer 架构的编码器部分用于学习词在给定上下文下词的 Embedding 表示。考虑到语言模型任务为从左往右或从右往左预测下一个词的自回归任务,因此若采用该模式每个词无法依赖于当前上下文下后续词进行词向量表示。为了解决该问题,BERT 提出了两类预训练任务:
1.掩码语言模型任务
若采用 self-attention 并直接用于语言模型任务,则每次预测下一个词时由于 self-attention
机制会将下一个词的信息引入到当前词的表征中,当使用该词的表征用于预测下一个词
时,相当于将标注引入到了特征中,因此出现学习失效问题。为了解决该问题,BERT 提
出了如下解决方案:
从待预测序列中随机选择 15% 的位置用于预测任务
- 80% 的概率下将选取出的 15% 的位置对应的词替换为 [MASK]
- 10% 的概率下将选取出的 15% 的位置对应的词替换为随机词
- 10% 的情况下不对选取出的 15% 的位置对应的词进行词替换
引入 1.5% 的随机词,相当于对数据增加部分噪音,提升模型的鲁棒性。1.5% 的情况下保留原词是因为 fine-tuning 阶段并没有 [MASK] 词。
2.编码器自注意力
下一句预测任务
考虑到重要的下游任务譬如问答 (Question Answering) 任务,自然语言推理 (Natural Language Inference) 任务依赖于对两个句子的关系的理解,该信息在语言模型中没有直接体
现。因此 BERT 中同时设计了下一句预测任务,该任务的构建如下:
- 每个预训练序列由句子 A 和句子 B 构成
- 50% 的概率下句子 B 为句子 A 的下一个句子
- 50% 的概率下句子 B 不是句子 A 的下一个句子
实际构建预训练任务时是是首选设计好” 下一句预测任务”,生成该任务的标注信息,在此基础上构建” 掩码语言模型任务”,生成掩码语言模型的标注信息。考虑到预训练涉及两个句子,BERT 采用如下的输入信息表征方案:
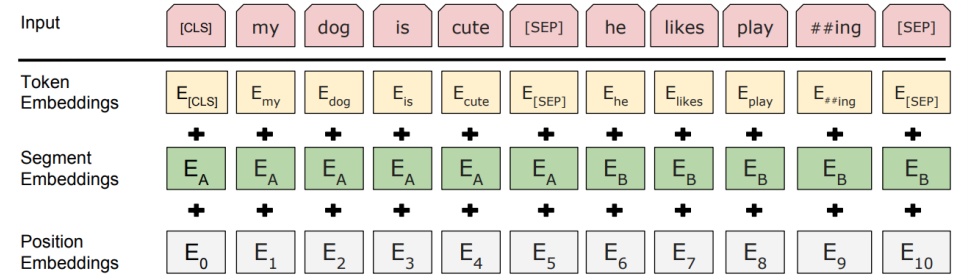
预训练阶段损失函数通过线性加权方法,同时进行上述两类任务训练。预训练阶段结束后将学习到每个词在特定上下文中 BERT 的表征信息,该表征信息即可用于下游的任务,如下是 BERT 表征用于不同类型的下游任务的 fine-tuning 方案:
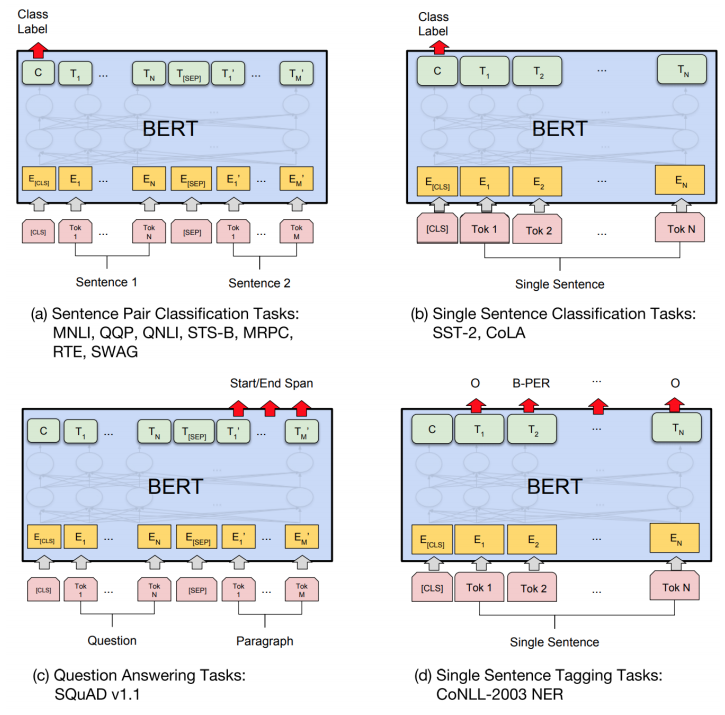
- 作者: Chris Yan
- 链接: https:/Yansz.github.io/2019/02/11/BERT简要介绍/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!