
前言
Pointnet开创性地将深度学习直接用于三维点云任务。由于点云数据的无序性,无法直接对原始点云使用卷积等操作。Pointnet提出对称函数来解决点的无序性问题,设计了能够进行分类和分割任务的网络结构,本文结合源码与个人的理解对于T-net网络和对称函数进行分析。
点的无序性
针对点的无序性问题实际上是文章提出了三个方案:
- 对于无序点集进行排序(Pointcnn)。
- 把点集当做序列进行处理,但是这种方法需要对输入点集做所有的排列变换进行数据增强。
- 使用对称函数,Pointnet使用的就是这种方法。
Pointnet网络主要使用对称函数解决点的无序性问题,对称函数就是指对输入顺序不敏感的函数。如加法、点乘、max pooling等操作。假设输入特征为NxD,N表示点数,D表示维度数,在max pooling作用下,取出每个维度上最大值的1xD的向量,每一维特征都与其顺序无关,这样便保证了对于点云输入顺序的鲁棒性。
点云的旋转不变性
Pointnet的解决方法是学习一个变换矩阵T,即T-Net结构。由于loss的约束,使得T矩阵训练会学习到最有利于最终分类的变换,如把点云旋转到正面。论文的架构中,分别在输入数据后和第一层特征中使用了T矩阵,大小为3x3和64x64。其中第二个T矩阵由于参数过多,考虑添加正则项,使其接近于正交矩阵,减少点云的信息丢失。
1. T-Net网络结构
将输入的点云数据作为nx3x1单通道图像,接三次卷积和一次池化后,再reshape为1024个节点,然后接两层全连接,网络除最后一层外都使用了ReLU激活函数和批标准化(batch normalization)。
论文中的T-net网络的实际结构并不复杂,我根据个人理解画出T-net的结构。
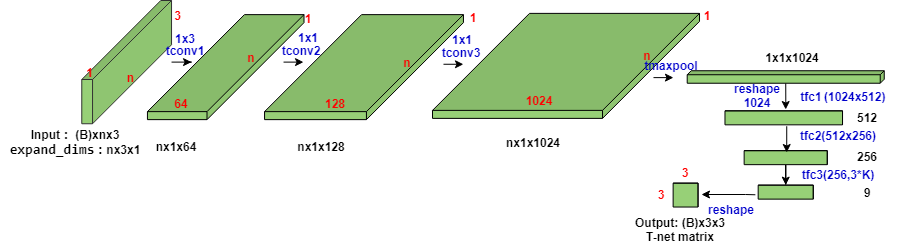
实际训练过程中,T矩阵的参数初始化使用单位矩阵(np.eye(K)), 参数会随着整个网络的训练进行更新,并不是提前单独训练的。很多文章提到T-Net对特征进行对齐,保证了模型的对特定空间转换的不变性,我其实不太理解这种说法。
实际上通过网络结构看出T-net结构是一个mini的Pointnet做特征提取,是个弱监督学习设计,我理解为需要训练一个矩阵对输入点(或者深层特征)进行坐标吧变换,个人认为这样的设计实际上是可以保留原始点云的部分特征,为后面的concat操作提供更多特征。源码中在点云分类部分使用到了T-net,点云分割部分可以不用,对结果并没有太大的提升,原因在于pointnet结构自身不能学到点云点的局部联系,因此即使加入类似结构的T-net也是一样。
- models/transform_nets.py中的网络实现
1 | def input_transform_net(point_cloud, is_training, bn_decay=None, K=3): |
针对64x64的网络设计与3x3的一样,只是改变了K值,对于文章提到让特征转化矩阵接近正交化,这样特征损失更小,这部分的实现是在分类任务对损失函数加入正则项,及添加权重reg_weight=0.001,下文分析中会标出。
2. 点云分类部分
这部分主要分析训练代码和点云分类模型的设计
- train.py
1 | # 参数输入处理 |
原始点云nx3与T-Net训练后得到的3x3旋转矩阵相乘后,可以理解为变换为一组新的坐标下的点云数据。
- models/pointnet_cls.py中的代码
1 | # 1.原始点云与3x3的T变换矩阵 |
对于pointnet_cls_basic.py没有使用T-net的点云分类,网络结构更容易理解,比加入T-net的结构性能略低。
3. 点云分割部分
- 点之间的相关性问题
针对与分割物体上的问题与分类任务不同,分类任务中特征经过max pooling得到一维特征向量,它包含了全局信息,再经过全连接网络,得到1*K的k个类别预测得分即为分类结果。而分割任务中,需要对每一个点输出所属类别,使用类似二维图像分割的上采样过程(跳步连接skip-links)。Pointnet针对分割任务也使用了类似图像分割任务的,高层全局信息与底层局部特征结合的思想。
针对Pointnet论文作者提供的版本(Tensorflow)的源码如下:https://github.com/charlesq34/pointnet
对于pointnet源码其余部分的介绍不详细展开,根据个人理解将源码的结构与功能设计展示如下:
.png)
分割部分的代码实现主要在part_seg/(部件分割)和sem_seg/(场景分割)下。其中part_seg中底层局部特征与高层全局特征的连接(concat)使用到了各层特征。
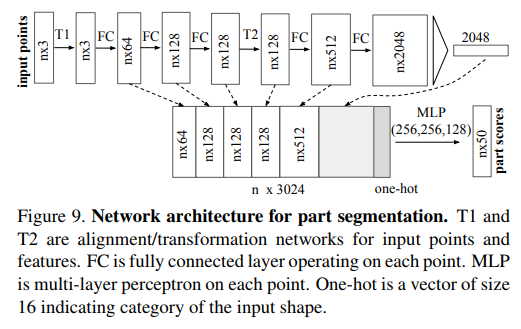
sem_seg/model.py场景分割中需要注意论文使用的S3DIS数据维度不再是3维而是更高的9维度(XYZ+RGB+相对于房间的标准化后的位置信息),针对特征连接部分使用高层全局特征(B*1024)接全连接降维到128,然后与高维特征自身做concat,不是采用论文中提到的方式。
而论文中提到的分割结构实际是在models/pointnet_seg.py中实现,即max pooling后的1D特征向量,使用tf.tile()复制n份(n个特征点),与之前网络得到的 n * 64特征矩阵分别concat。得到一个n(64+D)的特征矩阵,再经一系列的特征变换操作,得到每个点的分类结果。
结语
本文主要结合代码层面总结了pointnet网络的分类和分割任务的实现。主要是理解pointnet是如何做到直接从原始点云数据中提取高维特征,并且解决好点云的特性。实际上基于pointnet结构可以进行很多任务,比如点云配准,物体检测,3D重建,法向量估计等,只需要根据具体任务合理修改网络后几层的结构,利用好网络提取的高维特征。
针对pointnet存在的点与点之间相关性的缺失,在pointnet++中使用局部采样+分组+pointnet的结构进行解决,并考虑到了点云的稀疏性解决方案,之后很多深度学习的研究在此基础上展开,习惯上称为pointnet家族(point-wise MLP),比如Frustum,flowNet 3D,LSAnet,PAT等等。个人认为更高的准确度需要点云等3D数据与图像结合进行深度学习训练,将图像的高分辨率优势借鉴进来会有更好的效果。
源码地址:
1.原论文实现代码
https://github.com/charlesq34/pointnet
2.基于pytorch实现:
https://github.com/fxia22/pointnet.pytorch
https://github.com/yanx27/Pointnet_Pointnet2_pytorch
- 作者: Chris Yan
- 链接: https:/Yansz.github.io/2020/03/10/pointnetcode/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!